How Fast Can You Go? A Concurrency Evaluation Between Python, JavaScript and Go

Concurrency is a key paradigm for the development of scalable, performant and stable software engineered applications. Languages like JavaScript and Python have popularised asynchronous event-driven patterns in favour of multi threaded programming. Threading has shown to be insufficient with respect to performance, memory consumption and shared state as demonstrated by performance metrics for Nginx and Apache servers. In this post we will examine asynchronous performance against a relative newcomer to web scale concurrency - Golang (Go).
Evaluating the three languages
JavaScript and Python have served me well for the majority of my projects and are an absolute pleasure to develop in particularly when dealing with web related tasks. I've enjoyed these languages in my academic work and publications, industry-based tooling and most recently with personal project work. You may have seen in recent blog posts I've written about a domain permutation tool - Domainsync built in JavaScript, and an interface to Burp's REST API developed in Python.
Before embarking on another security scanning tool I wanted to evaluate whether my go-to languages were in fact the best choices in terms of speed and accuracy, or whether it's worth biting the bullet and developing in a completely new language. To assess this I've created one file for each of the three languages [fast., go, py, js], all utilising the best concurrency methods supported by the languages.
The process is as follows:
- Take an input file of URL's
- Parse the input file and create an array out of it
- Pass the array to the most suitable concurrency task supported by the language
Javascript
It was decided to make use of JavaScript's built-in concurrency model - Promises. We opted for the Promises.all method that essentially creates an array of new fetch objects and attempts to resolve them all at once.
let urls = [...array of urls]
Promise.all(urls.map(url => // resolve the array of fetch promises
rp({uri: url}) // exec request-promises for each url
.then( res => console.log(res)) // print result
.catch( err => console.log(err)) // catch errors
))
.then(data => { // we are done
console.log('done')
})
Python
For Python, the asyncio python3 library was chosen due to behaviour similarities with async JavaScript.
## run
async def run():
sem = asyncio.Semaphore(MAX_LIMIT) # semaphor for maximum number of connections
url = args.url # Retrieve the url as an argument from the command line
clientsession = get_client_session() # Fetch all responses within one Client session
await process(sem, url, clientsession)
## process
async def process(sem, url, clientsession):
tasks = []
r = 10000 # number of async tasks to run
async with clientsession as session: # use an async session across all connections
for i in range(r):
task = asyncio.ensure_future(bound_fetch(sem, url.format(i), session))
tasks.append(task) # append the future to our tasks array
responses = await asyncio.gather(*tasks) # await on all tasks to complete
logger.debug('done') # we are finished
## bounded fetch
async def bound_fetch(sem, url, session):
async with sem: # ensure we have the semaphore prior to awaiting our fetch
return await fetch(url, session)
## fetch method
async def fetch(url, session)
resp, source = None, None
try:
resp = await session.get(url, timeout=60, allow_redirects=True)
source = await parse_response(url, resp)
except:
logger.debug('error occured')
finally:
if resp is not None:
await resp.release()
if resp:
await resp.release()
## main
loop = asyncio.get_event_loop()
future = asyncio.ensure_future(run())
loop.run_until_complete(future)
Golang
For Golang we've opted to use a built-in primitive, namely goroutines. The pattern used here is the producer/ consumer as illustrated in this article.
// dispatcher
func dispatcher(reqChan chan *http.Request, urls []string) {
defer close(reqChan) // close the channel when ready
for i := 0; i < reqs; i++ { // req's is the total number of requests to perform
req, err := http.NewRequest("GET", urls[i], nil) // initialise our request object
if err != nil { // error check
log.Println(err)
}
reqChan <- req // send the request object to our request channel
}
}
// worker pool
func workerPool (reqChan chan *http.Request, respChan chan Response) {
client := &http.Client{} // client init & timeout settings defined here
for i := 0; i < max; i++ { // max is the maximum number of concurrent routines
go worker(client, reqChan, respChan) // the go keyword instructs this method to run concurrently
}
}
// worker
func worker(client *http.Client, reqChan chan *http.Request, respChan chan Response) {
for req := range reqChan { // loop through requests on our requests channel
resp, err := client.Do(req) // perform the HTTP request via *http.Client
r := Response{resp, err} // map the HTTP response to the Response struct
respChan <- r // send the result back on the response channel
}
}
// consumer
func consumer(respChan chan Response) (int64, int64) {
var conns int64
for conns < int64(reqs) { // loop for total number of requests to perform
select {
case r, ok := <-respChan: // receive the response from respChan
if ok {
processResponse(r) // process the response
if err := r.Body.Close(); err != nil {
log.Println(r.err) // close and error log if failure occurs on close
}
conns++ // track no. of connections (this should be equivalent to # routines)
}
}
}
return conns // return no. of connections
}
// main
urls:= []string{..slice of URLs}
go dispatcher(reqChan, urls) // dispatcher holding a pointer to our requests channel
go workerPool(reqChan, respChan) // worker pool holding pointers to request and response channels
conns, size := consumer(respChan) // the consumer which processes our response channel
You may have noticed that we've ruled out sequential requests out of our evaluation - for argument sake these typically take orders of magnitude longer time to complete due to the wait time for each previous connection before moving onto the next.
Methodology
- Input file with 10,000 URL's
- Attempt to resolve fetching for all URL's simultaneously
- Print the time taken to complete in each language using the time command
For a fair and balanced test we assume the following:
- The URL's fetched are cached and therefore do not require hitting the origin servers (doing so would end up skewing the data due to inconsistent latency from the origin server)
- The tests are to be run on the same spec machine (2.9GHz Intel Quad Core i7, 16GB Memory)
- There are to be no additional network intensive processes on the test machine
- Multiple passes for each language test and averaged across all
- The
ulimitis set to 10k+ to ensure enough open file descriptors for establishing socket connections
Results
The results show that Go is the clear and obvious winner here. What we also found was that when increasing the number of concurrent requests, both Python and JavaScript were throwing exceptions mainly due to timeout related errors, while Go simply kept "going". The below stats are measured in seconds. (the lower the better)
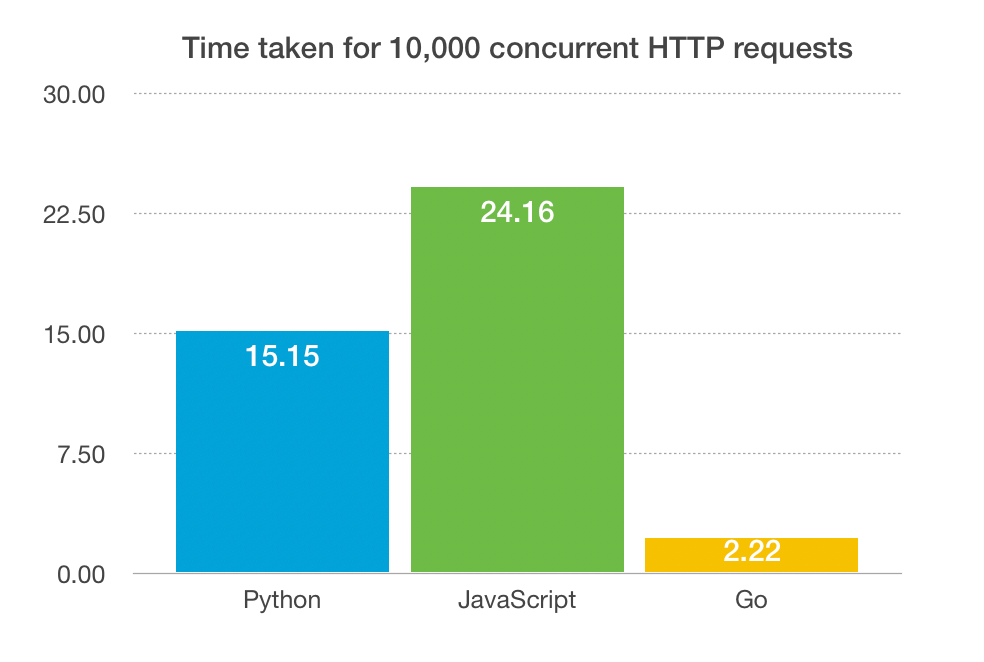
Limitations of Python and JavaScript
In the past I've found both languages to be fantastic choices for web based tasks, tooling and API development. The drawbacks to these languages only really manifest themselves when we push the languages to their resource limits. And it's where there's a lack of first class support for concurrency that these languages fall short.
For JavaScript you have the non-blocking event loop concurrency model which is touted as one of the more performant methods when dealing with HTTP on both the client and server side. This approach is referred to as the solution to the C10K problem that Apache servers traditionally suffered from. Nginx made the event loop approach wildly popular and demonstrated how to scale tens of thousands of concurrent HTTP requests by making use of asynchronous concurrency patterns (epoll, IOCompletionPorts), as opposed to multi-threading for request sessions. The memory intensive thread-per-connection approach that Apache uses is exactly why it's susceptible to Denial of Service attacks.
Python is a more mature language than JavaScript and has support for both user-space threads and asynchronous routines. A major drawback using Python with respect to concurrency is that, like Ruby, it suffers from the Global Interpreter Lock (GIL) and therefore does not have true support for a scalable, simplistic concurrency model. There are work-arounds for this problem, but again, they are supplemental solutions to the concurrency issue that the language core has not addressed.
Go on the other hand was developed by Google to address these problems head on. The Go programming language was the brainchild of Robert Griesemer, Rob Pike, and Ken Thompson, and was composed to address the concurrency model pitfalls exhibited by languages like Python, Java and C++. As such, the Go programming language has primitives like goroutines and channels baked in from the ground up giving the user the ability to spawn routines and communicate in a thread-safe manner with other parallelised tasks. Another key takeaway from using goroutines are the fact they're really eco-friendly with respect to memory overhead, while at the same time making it easy for the user to synchronise between tasks. You can think of channels as light-weight threads. But unlike threads in Java which require 1MB per thread just in overhead cost, goroutines can be spawned at a cost of ~2KB in memory without the need for additional libraries.
Conclusion
It's no secret that JavaScript's event-driven approach has yielded significant benefits over the years compared with traditional threading for concurrency, and that's why Nginx was shown to be superior to Apache with regard to the C10K problem. Python too has its many benefits particularly around speed, expressiveness, and a plethora of well-maintained packages making it the go-to language for professionals ranging from data scientists, academics, all the way through to information security pros. When it comes to performance and scalability, however, these languages may not be the most efficient choice when compared with concurrency-by-design languages like Go. Our experiments show that Go is the clear winner when dealing with tens-of-thousands of connections simultaneously, but requires a bit more work in terms of code structure and verbosity. In my view, these trade-offs are well worth it and end up paying dividends as code increases in complexity. Give it a Go and let me know your thoughts!